
Bonfire’s latest trick shows Google+ circles came a decade early
One of the best things about Google+ was the idea of sharing things using circles that you could define. Unfortunately, like Google Wave, it was a decade early.
For those who can’t remember, or who never experienced Google+, here’s a screenshot from Tojosan dated July 2011:
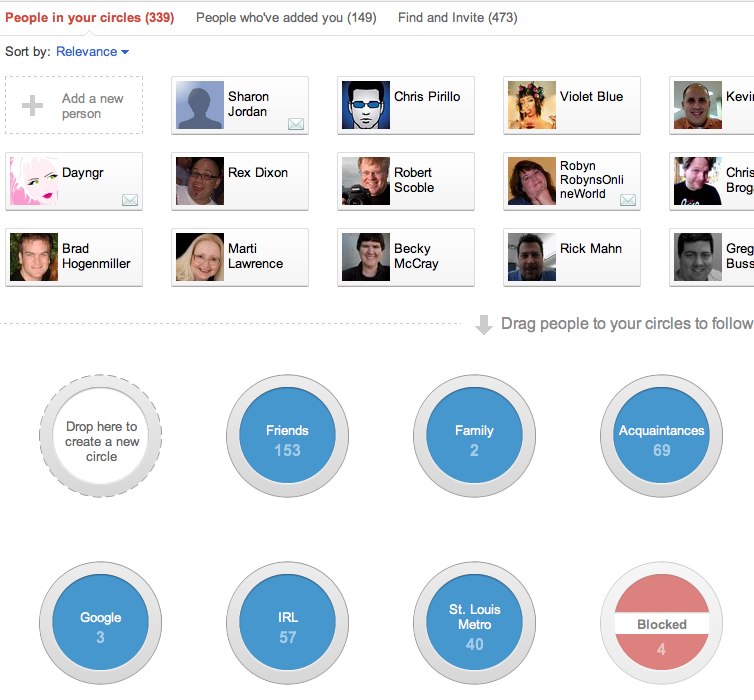
While the idea was a great one, the implementation wasn’t the best. Also, because it was launched at about the same time as mass adoption of social networks such as Twitter and Instagram, people didn’t really have the mental model of what was going on.
The important thing with Google+ circles (which I’ll now refer to just as ‘Circles’) was not that you put people in exclusive groups or categories. As the diagram below by Carrotkit demonstrates, there are things you want to share with one group (e.g. family), and things you want to share with another group (e.g. friends). However, members of these groups are not always mutually-exclusive:

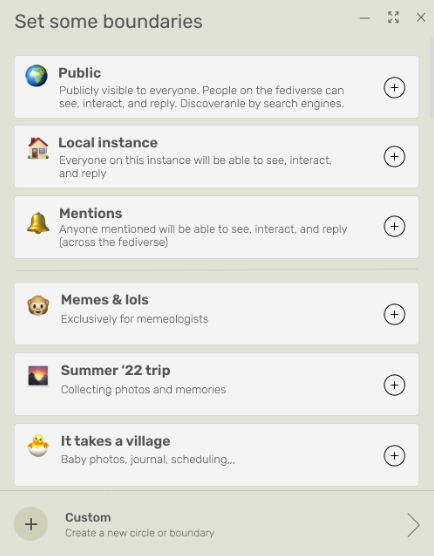
Thankfully, this approach is being resurrected by the Bonfire team under the less-snappily-named ‘granular boundaries’. However, the aim is much more ambitious.
As the announcement states:
Within bonfire, you now have the possibility to define circles and boundaries: a way to privately group some of your contacts and then grant them permissions to interact with you and each piece of content you share at the most granular level.
Boundaries go beyond the typical permissions on social media (i.e. who can see your content) and include a long list of verbs in order to represent all kinds of meaningful interactions and collaboration that should be possible on a real social network.
People don’t fit in binary boxes labeled “follower” or “friend”. Circles and boundaries are a way to empower us to come up with our own groupings and sets of permissions.
As Bonfire is a federated app toolkit, extensions will be able to make use of this functionality, for example going beyond simple roles such as ‘admin’ or ‘moderator’ of an instance. I’ve had a tinker with the Playground instance of Bonfire while it was enabled, and although initially a bit confusing, it works well.
What I’m hoping is that this bridges the gap between social networking as we know it (e.g. Mastodon, Twitter) and group chats (e.g. Signal, Telegram). If so, it could be useful for everything from professional purposes through to organising kids sport activities. Because, let’s face it, group conversations on the internet are a mess.
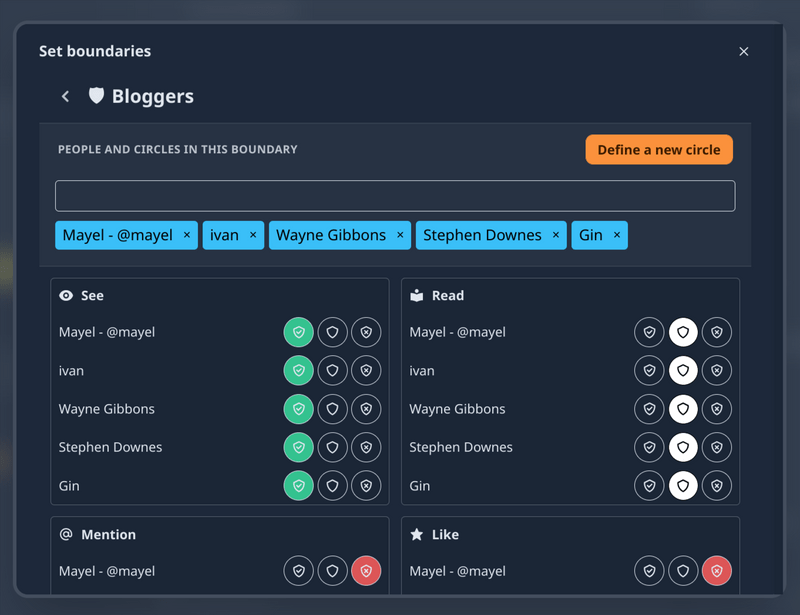
In the above example I’ve taken a screenshot of a circle I’ve created called ‘Bloggers’. This includes five people and I’ve explicitly given some permissions and blocked one person (sorry Mayel!) from liking or mentioning posts I share with that circle. This could be an absolute gamechanger in terms of how democratically-organised groups with a flat structure can be organised.
The list, for those interested, of what you can allow others to do is currently:
- See
- Read
- Mention
- Like
- Request
- Follow
- Boost
- Message
- Delete
- Tag
- Edit
- Create
- Flag
- Reply
Ivan and Mayel, the core team behind Bonfire are putting in an application for more NLnet funding to work on this functionality. I’ve just applied to NLnet too for a simple badge-issuer that I think could eventually be turned into a useful Bonfire extension. If and when that happens, this level of granularity will be extremely useful to build upon!

.png){kind=link}