Winnowing the MoodleNet project down to MVP size

Note: this post refers to the MoodleNet project that I’m leading. More on that can be found here: moodle.com/moodlenet
Context
As a knowledge worker, you can’t win. If you do your job well, then the outputs you produce are simple and easy to understand. It’s your job to deal with complexity and unhelpful ambiguity so that what’s left can comprehended and digested.
In a way, it’s very much like the process of writing for an audience. We’ve all read someone’s stream-of-consciousness email that said much but conveyed little. Good writing, on the other hand, takes time, effort, and editing.
The problem is that high-quality knowledge work looks easy. Long hours of thinking, discussing, and experimenting are boiled down to their essentials. You just see the outputs.
Perhaps the most obvious example would be brand redesign: almost no matter what’s produced, the response is usually that the process resulted in money wasted. That’s even more true when there’s public money involved.

As a result, logo designers tend to share the process which got to that point. They share iterations towards the final idea, any rejected ideas, and the conversations with people who had some input into the process.
Likewise, all knowledge workers should show their work, as Austin Kleon puts it. This not only proves the value of the work being done, but invites commentary and constructive criticism at a time when it can be useful — before the final version is settled upon.
Process
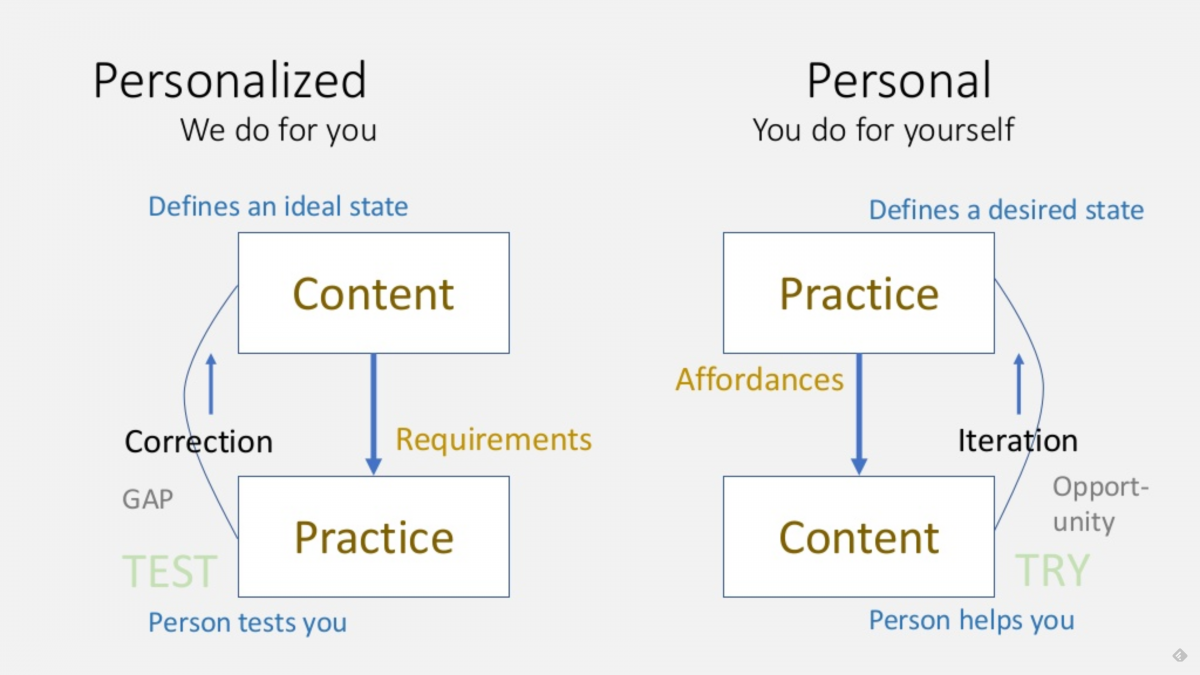
A Minimum Viable Product, or MVP, is “a product with just enough features to satisfy early customers, and to provide feedback for future product development.” However, in my experience, there’s a few stages before that:
- Research: whoever’s in charge of the project (in this case, me!) situates themselves in the landscape, talks to lots of people and does a bunch of reading.
- Hypothesise: the same individual, or by this point potentially a small team, comes up with some hypotheses for the product being designed. A direction of travel is set, but at this stage it’s only as granular as north, south, east, or west.
- Design: a small team, including a designer and developer, take a week to ‘sprint’ towards something that can be mocked-up put in front of users. The result is the smallest possible thing that can be built and tested.
- Prototype: developers and designers come up with a working prototype that can be put in front of test users within a controlled environment. Sometimes this uses software like Framer, sometimes it’s custom development, and sometimes it’s powered by nothing more than Google Sheets.
- Build: the team creates something that can be tested with a subset of the wider (potential) user base. The focus is on testing a range of hypotheses that have been refined through the previous four processes.
Following this, of course, is a lot of iteration. It may be that the hypotheses were shown to be invalid, in which case it’s (quite literally) back to the drawing board.
Where we’re at with MoodleNet
Right now, I’m working with colleagues at Moodle around a job ‘landscape’ for a Technical Architect to join us in the next few months. In the meantime, we’re looking to work with a design and development consultancy to take us through steps 3-5.
It gets to the stage where you just need to build something and put it in front of people. They either find it useful and ‘get’ what problem you’re helping them solve, or they don’t.
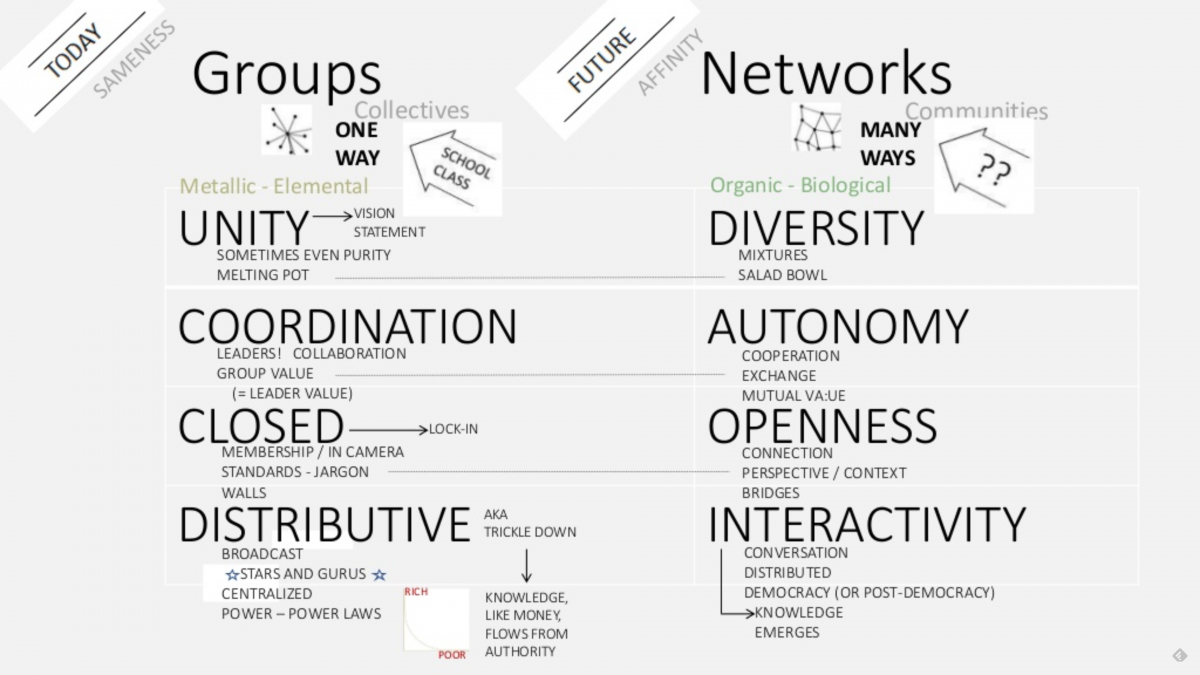
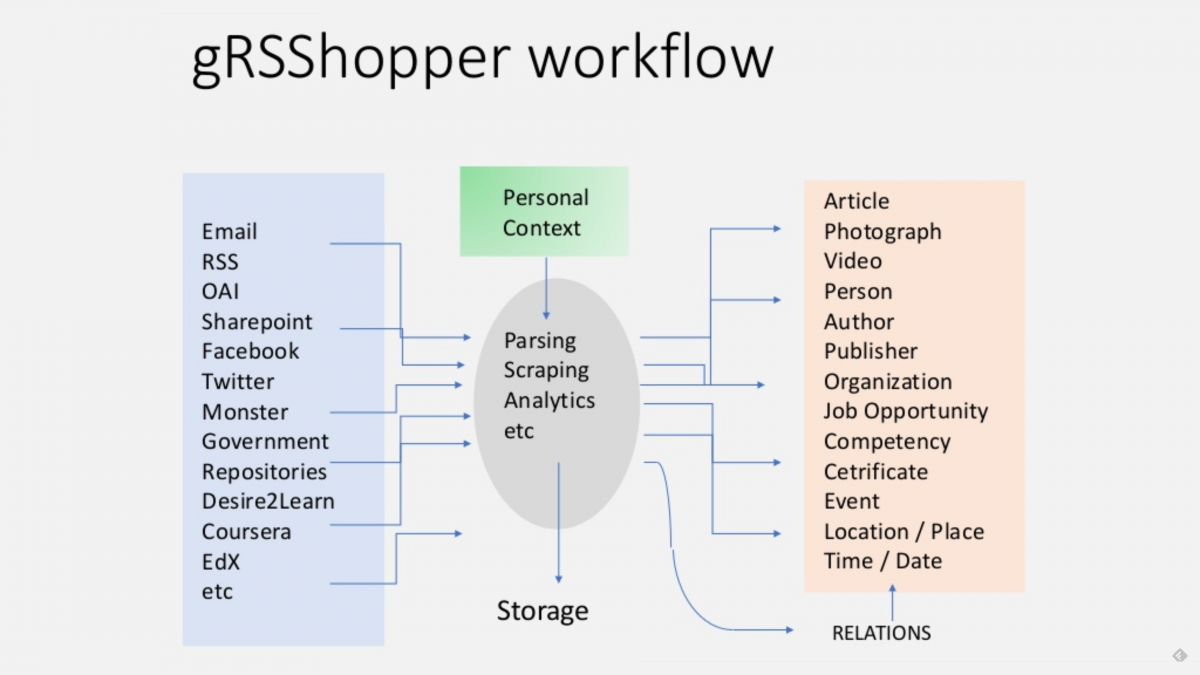
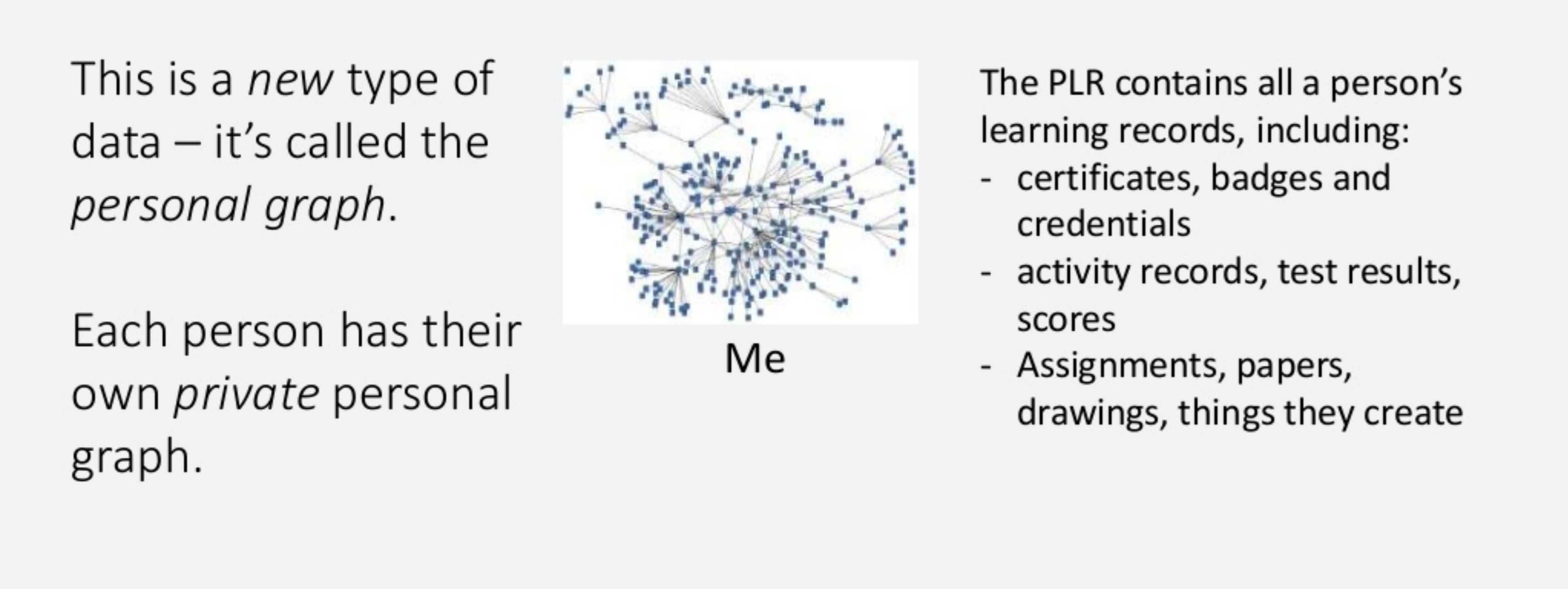
You can’t be too wedded to your hypotheses. As project lead, I was sure that a federated approach based on an instance of Mastodon was the place to start, until I spoke with some people and did some thinking and realised that perhaps it wasn’t.
And, of course, it’s worth reminding myself that there’s currently the equivalent of 0.8 FTE on this project (I work four days per week for Moodle). Rome, as they say, wasn’t built in a day.
Image: HEAVENLY CROP by American Center Mumbai used under a CC BY-ND license