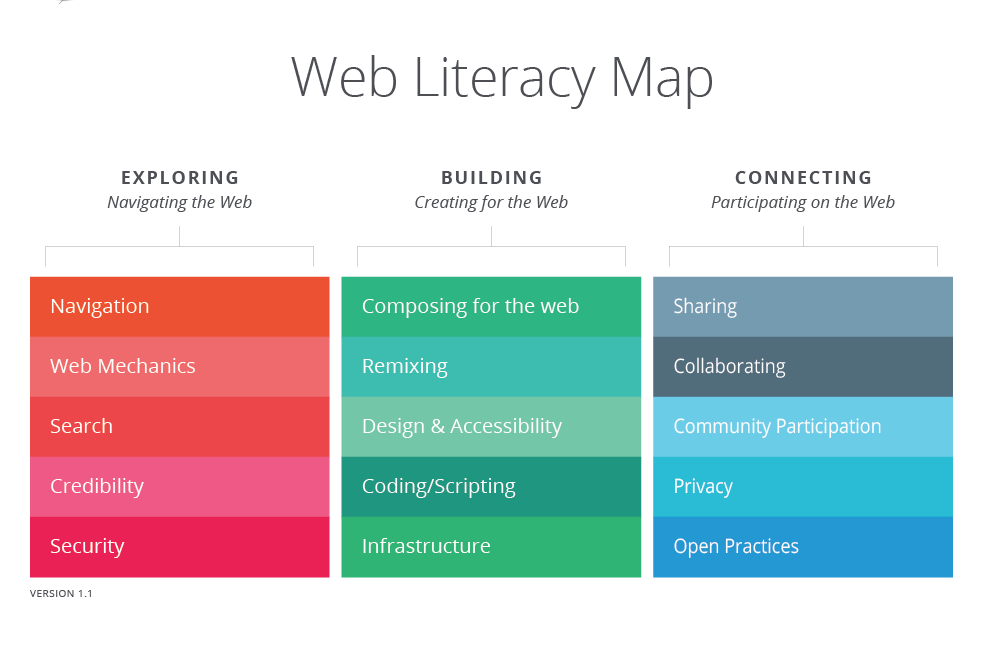
Peak centralisation
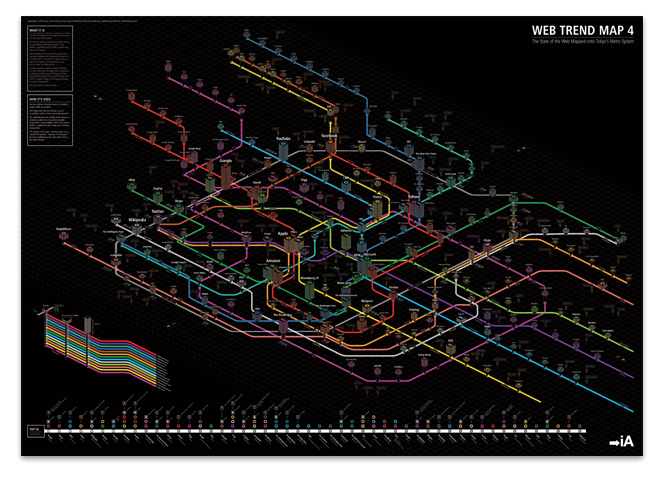
Information Architects' Web Trends Map 4 (2009)
Information Architects' Web Trends Map 4 (2009)
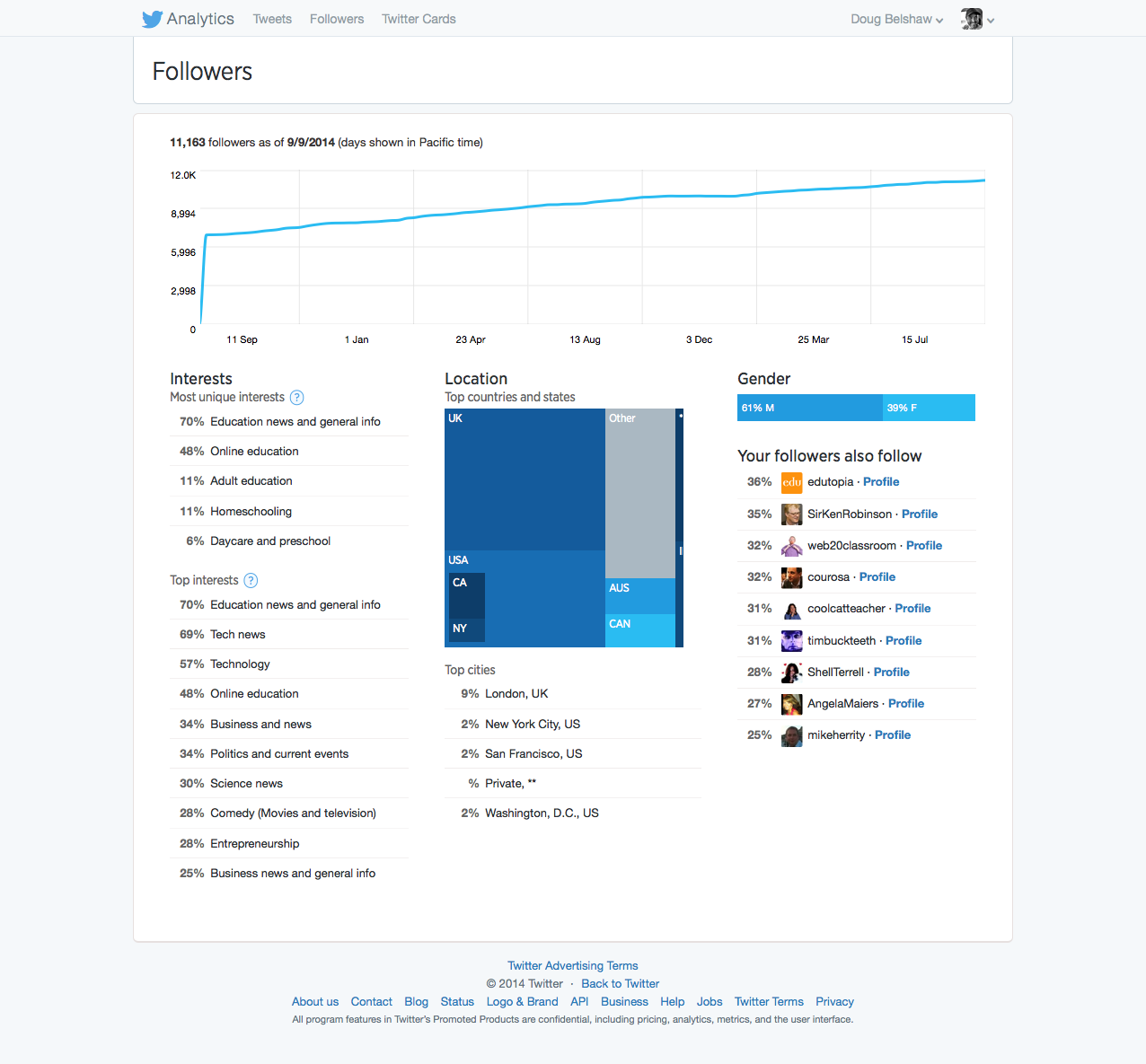

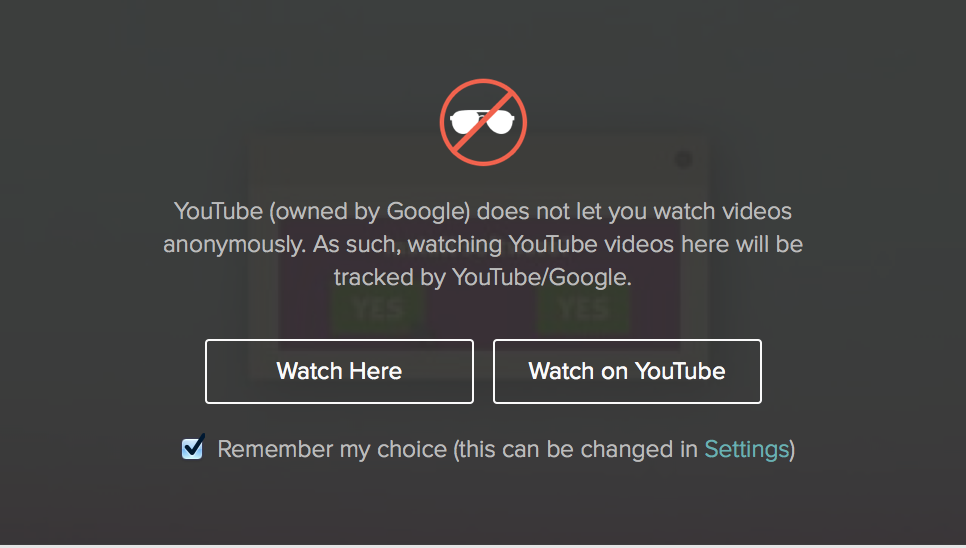
What happens when you search for videos via DuckDuckGo

CC BY-NC-SA Guy Fawkes
Taken from Badge pathways: part 1, the paraquel (Casilli, 2013)
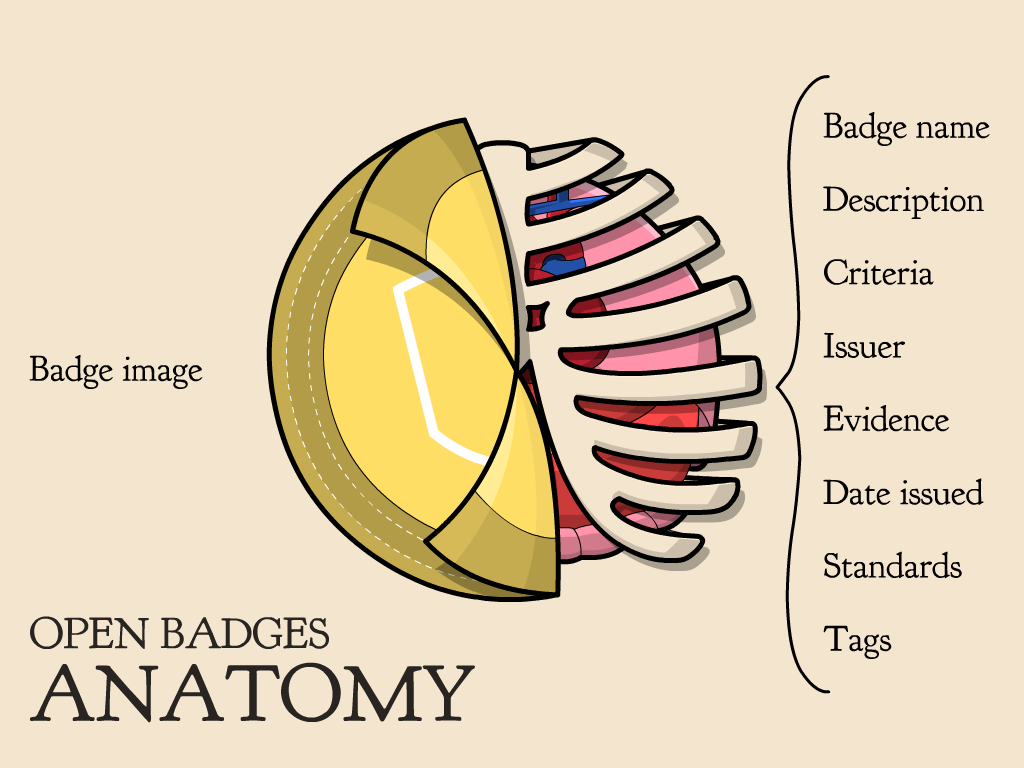
CC BY-SA Kyle Bowen