Yesterday was my last contractual day at Moodle, as I’ve been using up my remaining annual leave since Friday 19th June. This post is for the record, as my post celebrating the release of v1.0 beta on the MoodleNet blog was taken down.
In late 2017 I was happily consulting with various organisations when I was approached by Moodle to lead a new project. The ‘brief’ was a couple of pages of notes with some general thoughts which I turned into a white paper. It detailed how Moodle’s existing moodle.net repository could become a federated social network and decentralised digital commons. So, in January 2018 I joined Moodle’s management team, working four days per week, and slowly building a talented (part-time) team.
The history of what the MoodleNet team achieved can be seen through the 2018 and 2019 retrospectives. I’d like to thank Mayel, Ivan, James, Karen, Ale, Antonis, and Kat for being amazing colleagues. It truly was a pleasure working alongside them. This year, the team ensured we released v1.0 beta and successfully integrated with Moodle LMS v3.9.
(As a quick aside, Moodle’s legal counsel has been kind enough to get in touch. They reminded me that my contract included a confidentiality clause which remains in force after it ends.)
In May 2020, I resigned. A few days later, there was some unrelated drama which involved a tweet from Moodle’s CEO which I wrote about in Weeknote 23/2020. What hasn’t been documented anywhere, and which I’m not going to go into here for the reason given above, is what subsequently happened internally at Moodle HQ. Suffice to say that all but one of the talented and committed MoodleNet team decided to quit.
There’s more I could say about what happens when organisations get external funding. I could talk about some of the mis-steps the team made while experimenting and innovating. I perhaps could even discuss psychological safety at work. Ultimately, though, once I’ve finished my course of therapy, I will look back on my time at Moodle with pride. The team we managed to assemble took MoodleNet from an idea through to something pretty amazing. I’m so pleased most of the team are exploring other avenues to continue working on it.
I learned a lot at Moodle and I’m looking forward to using the best of it in my work through We Are Open, the co-op I helped set up four years ago.
This week, I’ve been based at home, settling into my new rhythm of working for Moodle on Mondays, Tuesdays, and Fridays, and We Are Open co-op on Wednesdays and Thursdays. I have to say, I like it.
When I tell people that I’m part of a co-op, people are often interested in what I can only refer to as power dynamics. How do decisions get made? Who’s in charge? How do you allocate work?
I can certainly answer those questions, but it’s the difference between explaining, for example, the act of swimming verbally, and getting into the water and doing it yourself. Like goldfish, we forget the ‘water’ we already swim in is one that takes for granted coercive power relationships. Instead, with the co-op, as members we rotate roles and discourage permission-seeking.
This week, we realised that, given the amount of potential work coming in, we really needed a project management solution. In an organisation with coercive power dynamics, this would be decided by fiat, or by the ‘management team’.
In our co-op, we instead took a different approach. Some members of We Are Open are available to work almost full-time. Some, like me, are available a couple of days per week. Others, right now, have very little availability.
So we allowed those who would be using the project management solution the most, and who were most interested, to do the research, and then suggest an option.
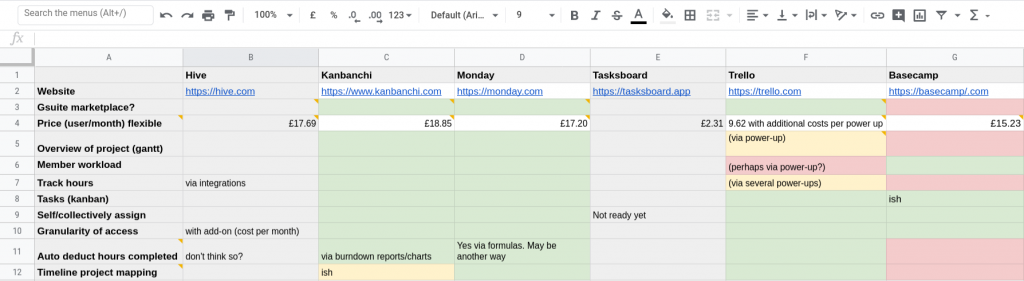
Project management tool comparison spreadsheet
This doesn’t have to be complicated, nor does it have to be based entirely on functional requirements. In the end, Gráinne Hamilton and I spent some time, both synchronously and asynchronously, with a few solutions.
What I found particularly interesting was that Gráinne and I had quite different requirements and assumptions going into this, but managed to find something that satisfied the collective needs of the co-op. (Note that the requirements down the left-hand side of the spreadsheet came from our meet-up in London the week before last.)
Once we’d chosen a solution to put forward, we shared our spreadsheet (which also included some comments you can’t see in the screenshot) and put it to a vote in Slack. The options were ‘Yes’, ‘No’, and ‘Need more info’. Every member voted in favour of our proposed solution, which in this case happened to be Monday.com.
When describing this kind of approach, people tend to call it ‘democratic’ and, to some degree, it is. But that’s just part of it. The main piece of the puzzle for me is ensuring alignment, which you get through healthy power dynamics.
11 Steps Towards Healthy Power Dynamics at Work (Richard D. Bartlett)
This is the kind of approach that you can use in any organisation. You don’t have to be yogurt-knitting vegans to get started with it.
For example, as Product Manager for MoodleNet, I meet 1:1 with every member of the team once per month. While I may not use the language in the above diagram, during these meetings what I have in mind during these meetings, as well as the weekly team meetings, is to increase reduce the ‘power-over’ that is implicit within hierarchies while increasing ‘power from within’.
Because of the intersecting injustices of modern societies, the degree of encouragement you receive when you’re growing up will vary greatly depending on many factors like your personality, gender, physical traits, and cultural background. If you want everyone in your org to have full access to their power-from-within, you need to account for these differences.
Richard D. Bartlett
What I’ve found in my career to date is that, no matter how they act in other situations, in 1:1 meetings, people are looking for reassurance and encouragement. The hard part is doing that without reinforcing a coercive power dynamic.
So this week was full of meetings, but thankfully not the boring type, but the kind that are focused on actions and outcomes. For example, in addition to meeting 1:1 with several of the MoodleNet team, I met with:
Sander Bangma who leads the Moodle LMS team about integration between our two products. We used a document we’d already been working on to make decisions about scope.
Martin Dougiamas, Moodle’s Founder and CEO, about MoodleNet resourcing and budgets. I then met with Mayel de Borniol to finalise a spreadsheet for the budget committee.
A potential client which I’ll not name right now. We keep these initial meetings to 30 minutes, investigate requirements, and then, if invited to, send a proposal.
Adam Procter who is a friend and generous supporter of Thought Shrapnel. He was looking for some advice about productivity and workload.
My therapist for my last CBT session for three months. I’m starting a period of consolidation after a marked improvement in my outlook on life over the past six sessions.
Olivier Wittorski and Emilio Lozano about gathering requirements for ways in which Moodle Workplace and MoodleNet could work together. This led to a document and a slidedeck with initial ideas and mock-ups.
As I discussed with Emilio, who became a father recently, when you have kids, your time becomes a lot more precious. This is doubly so when you split your time between two organisations. There’s less slack time, which is a good thing as it means you’re laser-focused on what needs to be done, and intolerant of distraction.
Next week, I’ll again be working from home all week. I’ve got some exciting co-op work to begin, as well as new functionality and features in MoodleNet to oversee. It’s the week before half-term, when I’ll probably be taking some time off to spend with the family.
As I’ve said in previous weeknotes, we’re getting our house ready to potentially sell, so I’ll be continuing to paint, and sand, and scrub, and buy random pieces of IKEA furniture…
TL;DR: I’m cutting down my Moodle days to allocate more time to We Are Open Co-op. I’ll still be leading the MoodleNet project.
In May 2016 I helped set up a co-operative with friends and former Mozilla colleagues called We Are Open Co-op. Since that time, we’ve done some inspiring work with fantastic clients, learned a lot about the co-operative economy, and worked in solidarity with similar organisations.
Since January 2018, and particularly during the last six months, I had taken a bit of a back seat in the co-op, focusing on my work at Moodle. However, the time has come for me to refocus my efforts to help continue building an organisation that I not only co-own but see as part of my life’s work.
It’s been an amazing journey over the last couple of years to take MoodleNet from an idea to reality. We did so with a small, part-time team who have gone above and beyond to achieve the vision of a federated, resource-centric social network for educators.
The future is bright for MoodleNet and I’ll be continuing in my role as Product Manager, ensuring the project has the necessary team and budget to make the required impact. I think it’s going to make a huge difference in the lives of hundreds of thousands of educators.
I’m sure it’s not necessary to note, but shall do anyway, that this decision was purely mine and not forced on me by anyone at Moodle. Over time, I’ve come to realise that my interests and talents are in the area of early-stage innovation.
So, from January 2020, I’ll be cutting back to three days for Moodle, meaning I’ve got more headspace for consultancy work. I’m excited to broaden my horizons again, getting involved in some of the really interesting projects that my co-op colleagues have picked up during the last few months, and working with new clients!
If you have any questions, I’m happy to answer them below. And if you’d like to work with the co-op, you might want to email: [email protected]